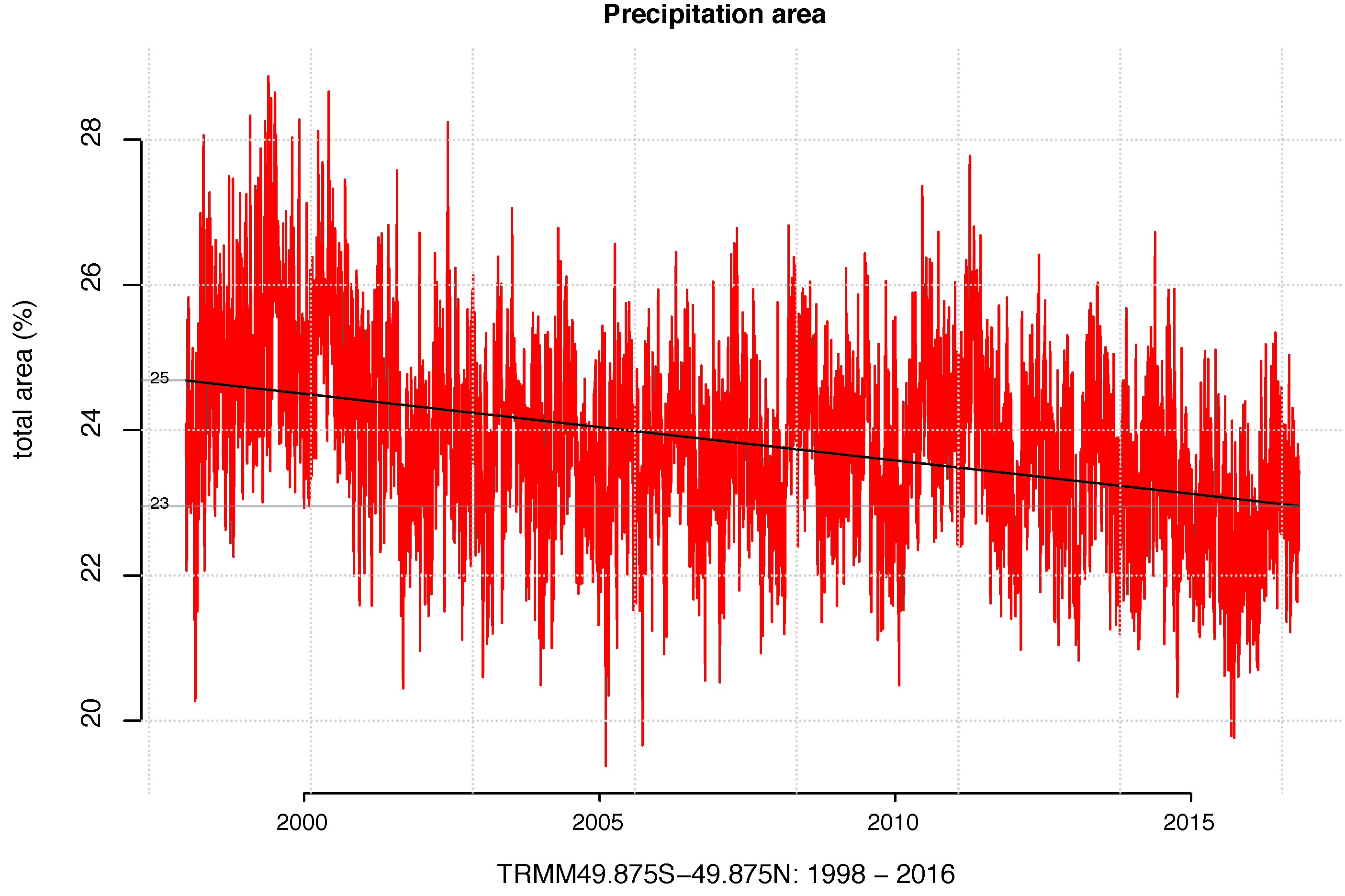
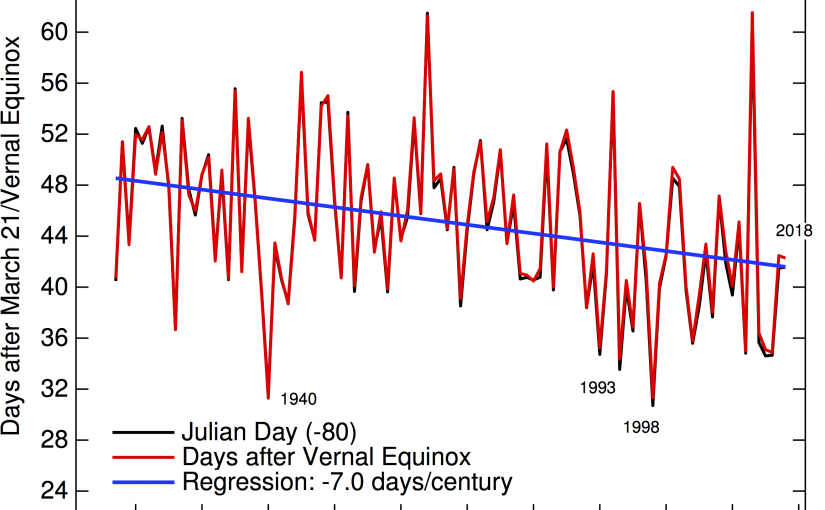
Good thing? Of course.*
I was invited to give a short presentation to a committee at the National Academies last week on issues of reproducibility and replicability in climate science for a report they have been asked to prepare by Congress. My
slides give a brief overview of the points I made, but basically the issue is not that there isn’t enough data being made available, but rather there is too much!
A small selection of climate data sources is given on our (cleverly named) “Data Sources” page and these and others are enormously rich repositories of useful stuff that climate scientists and the interested public have been diving into for years. Claims that have persisted for decades that “data” aren’t available are mostly bogus (to save the commenters the trouble of angrily demanding it, here is a link for data from the original hockey stick paper. You’re welcome!).
The issues worth talking about are however a little more subtle. First off, what definitions are being used here. This committee has decided that formally:
- Reproducibility is the ability to test a result using independent methods and alternate choices in data processing. This is akin to a different laboratory testing an experimental result or a different climate model showing the same phenomena etc.
- Replicability is the ability to check and rerun the analysis and get the same answer.
[Note that these definitions are sometimes swapped in other discussions.] The two ideas are probably best described as checking the robustness of a result, or rerunning the analysis. Both are useful in different ways. Robustness is key if you want to make a case that any particular result is relevant to the real world (though that is necessary, not sufficient) and if a result is robust, there’s not much to be gained from rerunning the specifics of one person’s/one group’s analysis. For sure, rerunning the analysis is useful for checking the conclusions stemmed from the raw data, and is a great platform for subsequently testing its robustness (by making different choices for input data, analysis methods, etc.) as efficiently as possible.
So what issues are worth talking about? First, the big success in climate science with respect to robustness/reproducibility is the Coupled Model Intercomparison Project – all of the climate models from labs across the world running the same basic experiments with an open data platform that makes it easy to compare and contrast many aspects of the simulations. However, this data set is growing very quickly and the tools to analyse it have not scaled as well. So, while everything is testable in theory, bandwidth and computational restrictions make it difficult to do so in practice. This could be improved with appropriate server-side analytics (which are promised this time around) and the organized archiving of intermediate and derived data. Analysis code sharing in a more organized way would also be useful.
One minor issue is that while climate models are bit-reproducible at the local scale (something essential for testing and debugging), the environments for which that is true are fragile. Compilers, libraries, and operating systems change over time and preclude taking a code from say 2000 and the input files and getting exactly the same results (bit-for-bit) with simulations that are sensitive to initial conditions (like climate models). The emergent properties should be robust, and that is worth testing. There are ways to archive the run environment in digital ‘containers’, so this isn’t necessarily always going to be a problem, but this has not yet become standard practice. Most GCM codes are freely available (for instance, GISS ModelE, and the officially open source DOE E3SM).
There is more to climate science than GCMs of course. There are operational products (like GISTEMP – which is both replicable and reproducible), and paleo-climate records (such as are put together in projects like PAGES2K). Discussions on what the right standards are for those projects are being actively discussed (see this string of comments or the LiPD project for instance).
In all of the real discussions, the issue is not whether to strive for R&R, but how to do it efficiently, usably, and without unfairly burdening data producers. The costs (if any) of making an analysis replicable are borne by the original scientists, while the benefits are shared across the community. Conversely, the costs of reproducing research is borne by the community, while benefits accrue to the original authors (if the research is robust) or to the community (if it isn’t).
One aspect that is perhaps under-appreciated is that if research is done knowing from the start that there will be a code and data archive, it is much easier to build that into your workflow. Creating usable archives as an after thought is much harder. This lesson is one that is also true for specific communities – if we build an expectation for organized community archives and repositories it’s much easier for everyone to do the right thing.
[Update: My fault I expect, but for folks not completely familiar with the history here, this is an old discussion – for instance, “On Replication” from 2009, a suggestion for a online replication journal last year, multiple posts focused on replicating previously published work (e.g.) etc…]
* For the record, this does not imply support for the new EPA proposed rule on ‘transparency’**. This is an appallingly crafted ‘solution’ in search of a problem, promoted by people who really think that that the science of air pollution impacts on health can be disappeared by adding arbitrary hoops for researchers to jump through. They are wrong.
** Obviously this is my personal opinion, not an official statement.


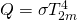
 (upper), the OLR measured by satellites (middle), and their difference.
(upper), the OLR measured by satellites (middle), and their difference.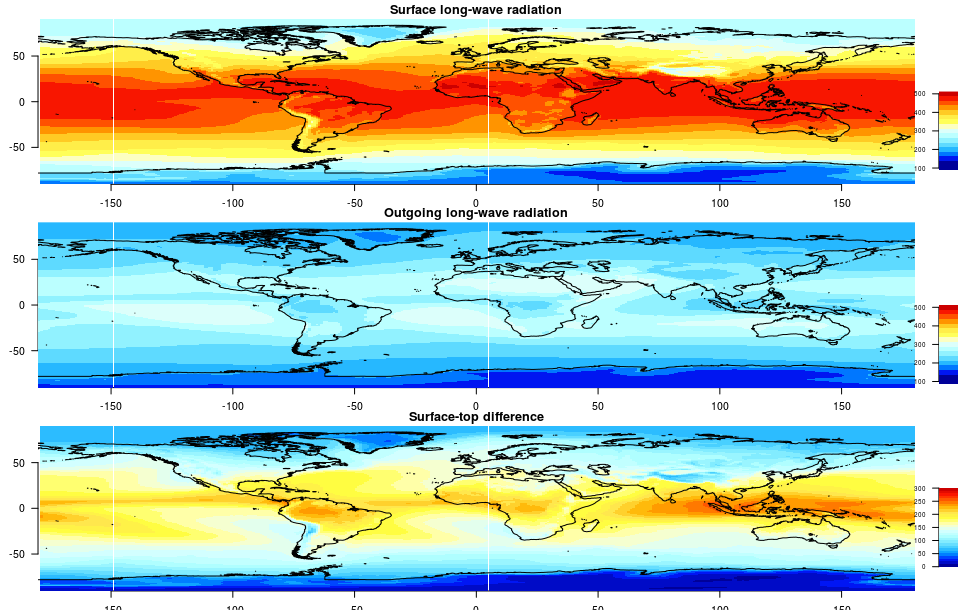

 over space estimated over
over space estimated over  grid-boxes, each with area
grid-boxes, each with area  :
: 
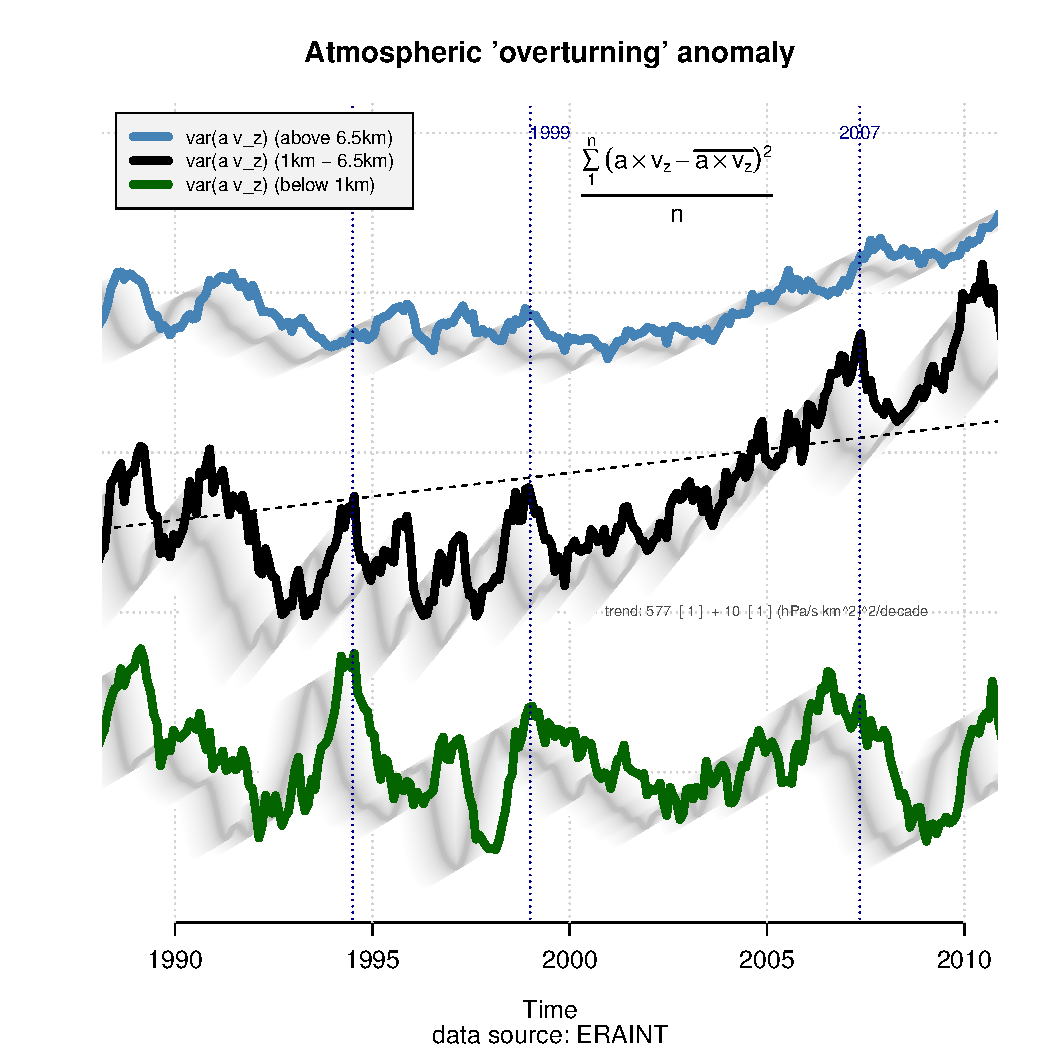
 in the figure (Source: Benestad (2016),
in the figure (Source: Benestad (2016), from reanalyses which provide data on the flow over a range of vertical levels and on a global scale. According to the figure above, there has been an increase in the global overturning indicator for the middle atmosphere (between 1 and 6.5 km above the surface).
from reanalyses which provide data on the flow over a range of vertical levels and on a global scale. According to the figure above, there has been an increase in the global overturning indicator for the middle atmosphere (between 1 and 6.5 km above the surface). . This indicator has a profound meaning for the hydrological cycle and is relevant for the question of flood risk and droughts.
. This indicator has a profound meaning for the hydrological cycle and is relevant for the question of flood risk and droughts.

 is returned a smaller
is returned a smaller  .
.